Enhancing 2D VLA Models with 3D Spatial Awareness
Vision-Language-Action (VLA)
3D Diffusion Policy
DINOv2
Depth Anything v3
Robot Learning
MuJoCo

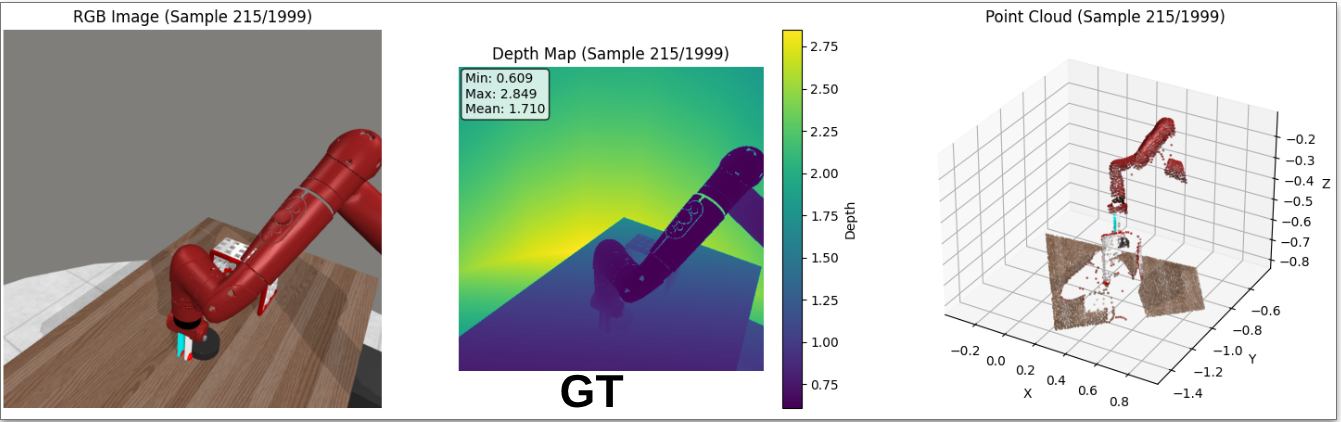
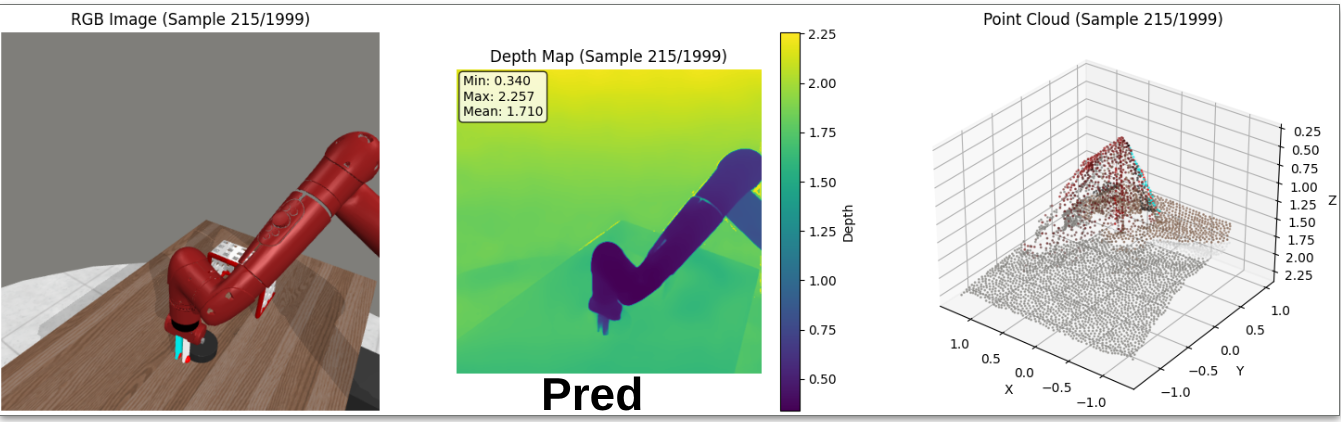
Research Objective
Investigate the practicality of converting single-view 2D RGB inputs into rich 3D scene representations for Vision-Language-Action (VLA) models. This work explores whether "software-only 3D" (pseudo-depth) can replace physical depth sensors, evaluates the performance gap between predicted and ground-truth 3D cues, and tests if VLAs can achieve superior geometric reasoning through lightweight spatial feature injection.
Key Features Achieved
- Dual Pipeline Architecture: Implemented two distinct methodologies: (1) generating pseudo-3D point clouds via Depth Anything v3 to drive a 3D Diffusion Policy, and (2) injecting spatially-aware semantic features from DINOv2 backbones.
- Pseudo-3D Scene Reconstruction: Developed a pipeline to unproject monocular depth maps into 3D point clouds, enabling 3D-native policies to operate on standard RGB video data.
- Semantic Feature Injection: Successfully utilized DINOv2 as a high-resolution feature encoder, achieving superior performance on dynamic tasks without explicit 3D reconstruction.
- Cross-Resolution Evaluation: Benchmarked model robustness across multiple input resolutions (128×128 to 512×512) and point cloud densities.
Challenges & Learnings
- Monocular Depth Artifacts: Observed that artifacts in high-resolution monocular depth estimation can cause performance degradation in geometrically complex tasks compared to lower-resolution, smoother predictions.
- Geometric Precision Gap: While software-only 3D excel at planar tasks, high-precision contact tasks like "Assembly" remain sensitive to the fidelity of predicted depth.
- Overfitting Risks: Identified a tendency for policies to overfit to perfect simulator depth, necessitating the development of noise-robust representations for real-world transfer.
- Computational Efficiency: Learned the trade-offs between dense 3D representation and lightweight semantic cueing for real-time robot control.
Quantitative Results
- Planar Task Success: Achieved a 100% success rate on the "Plate-Slide-Side" task using high-resolution monocular depth.
- Dynamic Task Performance: Demonstrated an 85% success rate on "Hammer" and 80% on "Basketball" tasks using the DINOv2 semantic feature pipeline.
- Resolution Stability: Maintained a 90% success rate on planar tasks even at low resolution (128×128), highlighting the efficacy of lightweight 3D cues.
- Benchmark Comparison: Evaluated against native 3D Diffusion Policy (DP3) baselines to quantify the "software-only" performance gap.